Ce bille est plus un mémo pour moi, mais autant partager les idées. ("Si tu ne sais pas, demande. Si tu sais, partage")
Un site web affichant des événements, ne propose que la liste des événements sur une page.
Pour voir chaque événement, il faut cliquer sur "voir plus" ce qui déclenche une requête web qui va chercher le contenu.
Sauf que ça me broute vraiment très fort. Impossible de comparer deux événements, de faire une recherche etc.
Donc :
- Via les outils de développement de firefox, dans la partie réseau on regarde la requête que le navigateur fait quand on clique sur "voir plus".
Ici sur l'image la première requête c'est l'affichage de la totalité des événements, la 2eme c'est le détail d'un événement.
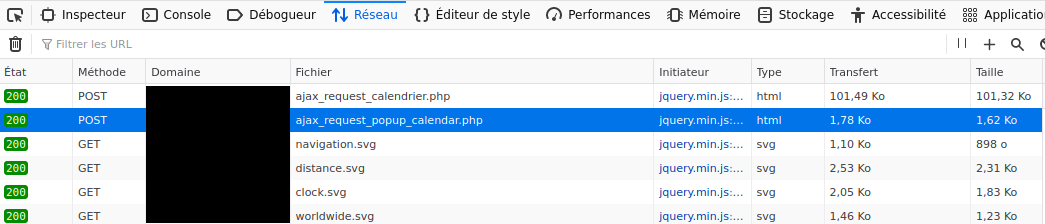
- On fait "clic droit -> copier la valeur -> copier la valeur comme cURL.
On ouvre un terminal, on copie-colle la requête (mais on ajoute un -k entre curl et le reste pour ne pas voir les erreurs de certificat)
Donc un truc comme
curl -k 'site web' XXXXXXXXXXX &id=54605 >> extraction
avec id=54605 comme identifiant pour l'événement. Et extraction comme nom de fichier où ça l'ajouter. (Petit détail l'enregistrement se fait avec un >> car contrairement au > ça ajoute le contenu a la fin du fichier. Vous allez voir pour la suite)
On regarde si ça fonctionne, oui c'est bien.
Donc a ce moment là on récupère la totalité des identifiants des événements. (Ils sont dans le premier fichier. La requête "ajax_request_calendrier.php"). Avec la solution qu'on préfère (find&remplace, grep, etc)
Perso vu que mon fichier avait plusieurs fois le même identifiant, j'ai rajouté une couche de uniq
On bricole un peu pour avoir une série de requête web (l'astuce étant de mettre des && entre chaque curl pour qu'elles se lancent a la suite).
Mais on ne fait pas trop de requête a la fois, sinon ça pourrait être considéré comme du DDos. Et donc soit le site nous bloque, soit (si le site plante ou autre) il pourrait y avoir une plainte.
On lance et ça donne un truc comme ça
On a donc un fichier extraction, qu'on renomme en extraction.html et on ouvre ça normalement.
Il ne reste plus qu'a adapter ça pour avoir un rendu acceptable